Christian Schluter, Mark Trede, January 2024, The Journal of Economic Inequality
»
We find that behind this development is the rapidly worsening inequality in the largest cities,
driven by increasing earnings polarisation
RESEARCH PROGRAM
The paper Spatial earnings inequality (SEI) is part of a wider ANR-DFG financed research programme that focuses on the evolution of inequalities in cross-sections and across the life-cycle. Why is inequality increasing, is inequality increasing everywhere at the same pace, who are the rich and how rich are they, are several rather fundamental questions, but the lack of reliable data too often stands in the way of getting answers: Survey data are well-known to be unrepresentative at the top (the so-called “missing rich” problem), while administrative data are often top-censored, rendering the endeavour to study the top without data somewhat tricky. We tackle these challenges with an empirical focus on Germany, reflecting partly the nature of the binational grant, partly the role of our partners (the DIW in Berlin) which hosts the German Socio-Economic Panel (SOEP). This international cooperation has enabled us to: (i) exploit data innovations, such as the new 2019 top wealth sample (SOEP-P), to study top wealth and income, and their best predictors; (ii) innovate methodologically by studying methods that can convincingly address the top-censoring problem, and (iii) innovate methodological by e.g. marrying inequality measurement and dynamic programming in order to accommodate the life-cycle, rather than providing a static perspective.
PAPER’S CONTRIBUTIONS
In SEI (JOEI, 2024, with M. Trede) we innovate by taking a spatial perspective to explain the dramatically increased earnings inequality in Germany. Measuring inequality locally at the level of cities / travel-to-work areas annually since 1985, we find that behind this development is the rapidly worsening inequality in the largest cities, driven by increasing earnings polarisation. In the cross-section, local earnings inequality rises substantially in city size, and this city-size inequality penalty has increased steadily since 1985, reaching an elasticity of 0.2 in 2010. To illustrate this, Figure 1 depicts a series of yearly scatter plots of inequality and city size (for full-time prime aged male earners in the West), as well as fits of a univariate regression line (solid black) sporting a remarkable R2 statistic, and a non-parametric estimate (dashed red) that confirms approximate linearity. Examining the local earnings distributions directly reveals that this is due to increasing earnings polarisation that is strongest in the largest places.
To get to these results, our research design had to address two interlinked challenges. An analysis of spatial inequalities requires spatially representative data, and earnings outcomes at the top. While surveys (such as the SOEP) usually report uncensored earnings, they are too small to be spatially representative. Hence our analysis of the evolution of spatial inequalities is based on a 2% administrative sample of all dependent employees, containing about 8 million year-person observations. The downside of this choice is that all administrative earnings data in Germany are topcoded at the social security threshold, resulting in a mean top-censoring incidence of about 12% in the yearly cross-section. We address the top-coding problem in these data directly within our estimation framework based on a parametric distribution approach that turns out to provide remarkable fits in the aggregate as well as at the level of cities (whilst outperforming standard but rather questionable imputation approaches).
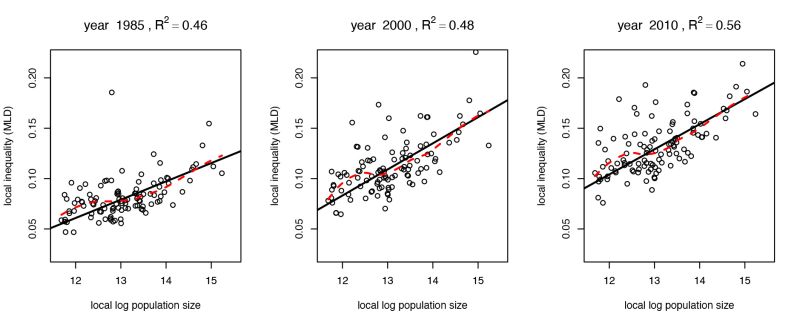
Figure 1: The growing city-size inequality penalty in Germany.
FUTURE RESEARCH
SEI is but one output from «Life-Cycle Inequality Dynamics (LINDY)” ANR-DFG project. In Routes to the Top (RTTT, König et al., 2023) we exploit the SOEP-P sample to study top wealth and income in Germany, validate it, examine the dependence between wealth and income, and use machine learning techniques to identify the top predictors in an analysis of who gets classed among the top 1%. (Machine learning in applied economics, and the merit of predictive studies in a literature that focusses on natural experiments, would be a subject of an entire lengthy newsletter column which will have to be deferred to another occasion.) In Beckmannshagen et al. (2024), we use the recent SOEP-RV project, which matches SOEP survey respondents and administrative social security records, in order to identify the best method of dealing with top-censoring in administrative data. Another cross-cutting theme is the study of the top distributional tail using so-called tail or extreme value indices, and we are making available a suite of stata functions labelled “beyondpareto” to the wider research community. Finally, in current work with M. Trede, we use a dynamic programming framework to model individual income and wealth outcomes over the life-cycle, which then informs a new unifying framework for dynamic and multidimensional inequality measurement.
REFERENCES
Beckmannshagen M., Retter I., Schluter C., Schröder C. , 2024, «Dealing with income censoring in register data». Work-inprogress.
König J., Schluter C. , Schröder C. , 2023, «Routes to the Top». DIW Discussion Paper 2066.
→ This article was issued in AMSE Newletter, Summer 2024.